
1. Geny i genom
Geny stanowią podstawową jednostkę dziedziczności. Geny są to odcinki DNA znajdującego się w jądrze komórkowym i mitochondriach, które kodują informacje dotyczące budowy białek lub krótkich kwasów rybonukleinowych (RNA). Zarówno białka jak i kwasy rybonukleinowe pełnią ważne funkcje strukturalne i funkcjonalne (w tym regulacyjne) w komórce. U człowieka znakomita większość genów koduje białka, które warunkują nie tylko pewne cechy fizyczne organizmu (takie jak kolor włosów czy oczu), są odpowiedzialne za prawidłowy przebieg różnych procesów zachodzących w naszym organizmie. Wadliwa budowa białek, a co za tym idzie, niemożność wykonywania przypisanej im funkcji może być powodem występowania wielu schorzeń. Obecnie uważa się, że człowiek posiada ok 20 -25 tys. genów kodujących białka. Całość informacji genetycznej zawartej w DNA nazywamy genomem. Jednak nie całe DNA zawiera informację, której sens rozumiemy. Występują w nim zarówno sekwencje kodujące białka/kwasy rybonukleinowe, nazwane sekwencjami eksonowymi jak i sekwencje niekodujące (introny). Funkcja intronów nie jest dobrze poznana. Co więcej, odcinek DNA składający się na jednostkę dziedziczności jaką jest gen, zawiera zarówno odcinki kodujące jak i niekodujące (introny) (rys.1)
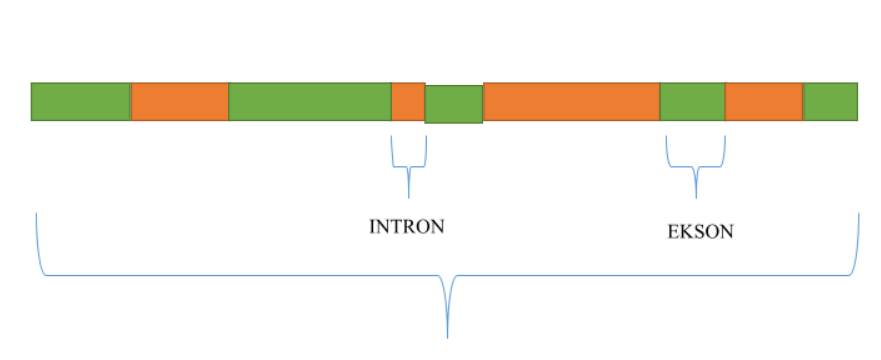
Rys. 1 Schematyczne przedstawienie budowy ludzkiego genu zawierającego sekwencje kodujące i niekodujące
Większość genomu człowieka zbudowana jest z sekwencji niekodujących, sekwencje kodujące stanowią około 1,5 – 3% całej zawartości genomowego DNA. Genom możemy podzielić na części nazywane chromosomami, każdy gatunek ma z góry określoną ilość chromosomów. W przypadku człowieka liczba ta wynosi 22+1 (22 chromosomy somatyczne oraz chromosom płciowy) i taka ilość chromosomów znajduję się w komórce rozrodczej danej osoby. W komórkach somatycznych (budujących ludzki organizm), w ich jądrach komórkowych znajduje się dwukrotność tej liczby, gdyż każdy chromosom posiada również swoistą „kopię zapasową” zwaną chromatydą siostrzaną. To jaka para chromosomów płciowych znajduje się w komórce warunkuje płeć danej osoby: XX (kobieta) , XY (mężczyzna).
2. Analiza WES
Wszystkie sekwencje kodujące w genomie nazywamy eksomem. Procedura, której celem jest odczytanie (czyli sekwencjonowanie) sekwencji kodujących DNA znajdujących się w jądrze komórkowym, a następnie ich analizy nazywa się WES. WES (od ang. Whole Exome Sequencing) pozwala na odczytanie i interpretację informacji genetycznej zawartej jedynie w sekwencjach kodujących, czyli eksonach. Ograniczenie analizy genomowego DNA jedynie do sekwencji kodujących wynika głównie faktu, iż według aktualnego stanu wiedzy, jak na razie wartość kliniczna płynąca z badania obejmującego również introny jest niewielka. Sekwencje kodujące i produkty ich ekspresji, czyli głównie białka powstałe w wyniku odczytania tej informacji przez komórkę, są znacznie lepiej poznane. Analiza sekwencji kodujących umożliwia nam określenie, czy dany gen zawiera w swoim zapisie jakieś zmiany, co może się bezpośrednio przełożyć na zaburzenie struktury i funkcji kodowanego przez niego białka. Informacje uzyskane w toku analizy WES mogą nam posłużyć do określenia czy i w jakim stopniu wykryte zmiany mogą być związane z wystąpieniem danego schorzenia, a w przypadku wykonywanej przez nas analizy, jak mogą one wpływać na płodność badanego/ej pacjenta/ki.
3. Zastosowanie analizy WES w badaniu genetycznych
uwarunkowań niepłodności
Białka pełnią kluczową rolę w funkcjonowaniu organizmu w tym również odpowiadają w dużej mierze za prawidłowy przebieg procesu prokreacyjnego. Biorą one m.in. udział w procesie powstawania i dojrzewania komórek jajowych (oogeneza) oraz plemników (spermatogeneza). Odpowiadają za regulację wszelkiego rodzaju procesów związanych z płodnością, a także warunkują m.in. rozwój zarodka i przebieg ciąży. Problemy związane z niepłodnością zarówno męską jak i żeńską mają swe źródło w wielu, przypadkach, nieprawidłowym funkcjonowaniu i/lub budowie białek związanych pośrednio lub bezpośrednio z procesami rozrodczymi. Przyczyny zaburzenia płodności to nie tylko problem nieprawidłowego funkcjonowania układu rozrodczego czy hormonalnego, ale trudna do pełnej identyfikacji i zdefiniowania ogromna liczba innych czynników (np. czynniki środowiskowe, dieta, czynniki odpowiedzialne za regulację ekspresji genów, dysfunkcja układu immunologicznego i wiele innych). Analiza WES daje unikatową możliwość odczytania kodujących sekwencji DNA pacjenta i porównanie ich z sekwencją referencyjną opracowaną na podstawie uśrednionego wzorca ludzkiego genomu, korzystając z wyniku takiego porównania możemy przyjrzeć się zmianom w obrębie dowolnego genu. Wzorzec genomu był możliwy do opracowania dzięki realizacji jednego z największych współczesnych projektów badawczych – Human Genome Project. W jego realizacji uczestniczyło ponad 2 tys. naukowców kierowanych przez amerykańskiego badacza, dr Francisa S. Collinsa. Główna część realizacji tego projektu została zakończona w 2003 roku. W analizie prowadzonej w celu identyfikacji genetycznych uwarunkowań niepłodności skupiamy się na analizie sekwencji tych genów, które według aktualnej wiedzy naukowej mają związek z zaburzeniami płodności męskiej i/lub żeńskiej w sposób pośredni lub bezpośredni. Jest to najbardziej szeroki z aktualnie dostępnych paneli badań, obejmujący znacznie szerszy zakres wykrywania genetycznych uwarunkowań zaburzeń płodności niż tradycyjne metody biologii molekularnej. WES jest szczególnie pomocnym narzędziem pozwalającym określić przyczynę zaburzeń zwłaszcza w przypadkach określanych mianem „idiopatycznych” (o nieznanej przyczynie). Wykorzystanie analizy WES do badań genetycznych uwarunkowań niepłodności jest innowacyjnym przedsięwzięciem Insytutu Genomiki i Medycyny Molekularnej (IGiMM) CMS Code (www.igmm.cmscode.pl). Badania w oparciu o analizę WES prowadzone są na całym świecie, głównie w placówkach naukowych, dużych jednostkach klinicznych i firmach prywatnych. Zastosowanie tej metody do identyfikacji genetycznych uwarunkowań zaburzeń płodności.Metoda ta jest pionierska i innowacyjana, a w przyszłości ma szansę zostania elementem rutynowej procedury diagnostycznej. Ogólny schemat wykonywania tej procedury w IGiMM CMS CODE przedstawia (rys. 2)
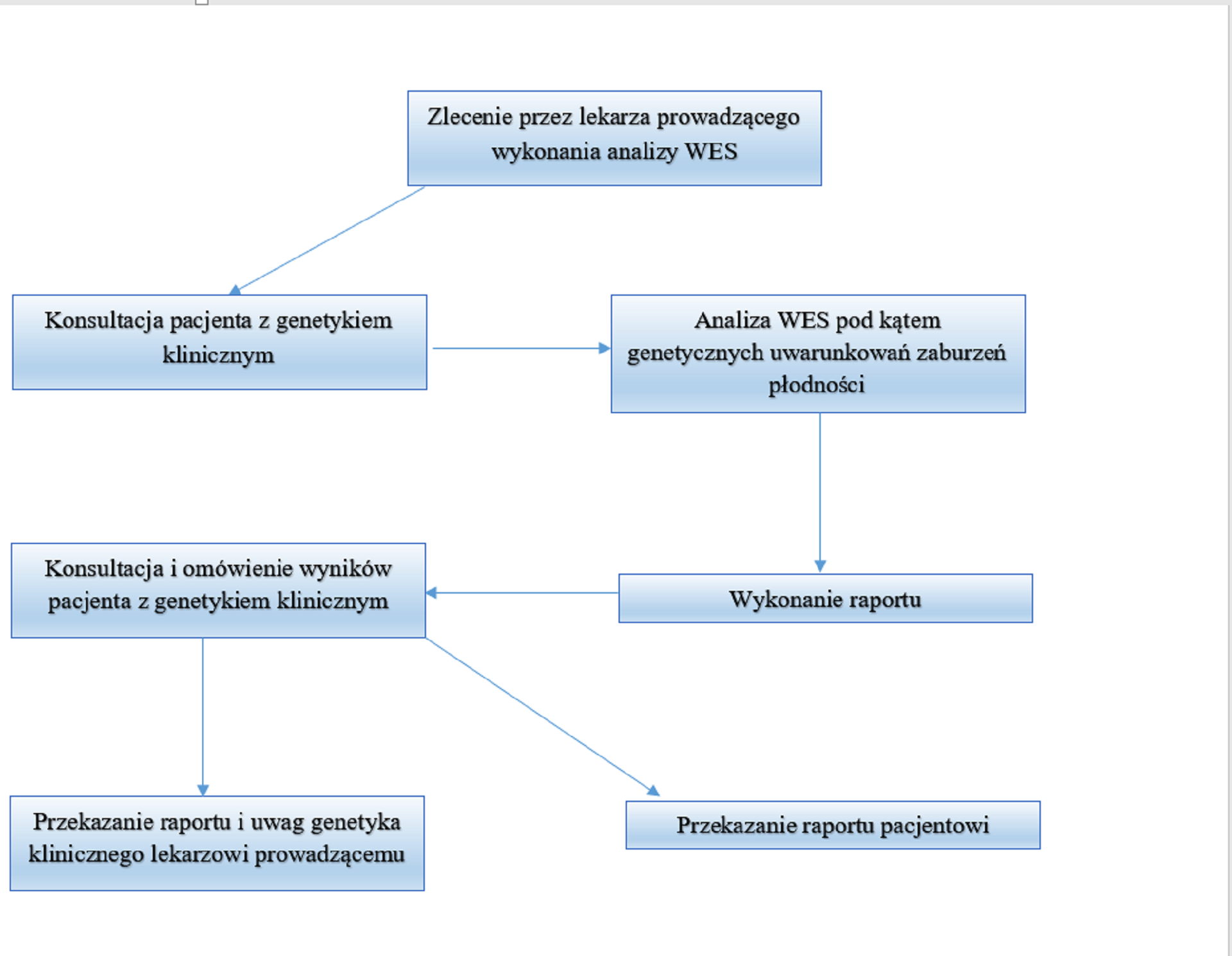
Rys.2 Ogólny schemat procedury wykonywania analizy WES
Głównym celem naszej działalności na poziomie badawczo-rozwojowym jest wdrożenie tej metody do praktyki medycznej w zakresie przyczynowego leczenie niepłodności.
4. Sekwencjonowanie (odczyt DNA), będące częścią analizy WES genetycznych uwarunkowań niepłodności, można wykorzystać znacznie szerzej.
Jak już wspomniano, białka są jednym z najbardziej podstawowych elementów strukturalnych i funkcjonalnych naszego organizmu. By dokonać analizy możliwie najszerszych przyczyn genetycznych uwarunkowań zaburzeń płodności, w których uczestniczą białka, dokonujemy odczytu całego eksomu (czyli większości lub prawie wszystkich genów kodujących białka), ale analizujemy tylko wybraną grupę genów i ich wariantów polimorficznych (czyli tych, które mają zmiany w swoim zapisie w stosunku do ich pierwotnych „wzorców”), a które na dzień dzisiejszy nauka łączy z możliwością ich wpływu na zaburzenia płodności występujące u badanego pacjenta/ki. Coraz częściej analiza WES wykorzystywana jest przede wszystkim w diagnostyce i personalizacji leczenia chorób nowotworowych, układu krążenia, chorób o podłożu genetycznym, a także w profilaktyce zdrowotnej. Zapis informacji genetycznej nie zmienia się zasadniczo przez cały okres naszego życia, od momentu zapłodnienia komórki jajowej i powstania zygoty, aż do śmierci. Ta część analizy WES, która polega na odczytaniu informacji genetycznej, dostarcza pacjentowi pewnego rodzaju „książeczki” z zapisem „planu budowy” białek tworzących jego organizm. Przeprowadzenie odczytu zapisu informacji genetycznej organizmu badanego pacjenta może więc posłużyć nie tylko do głównego celu, jakim jest poszukiwanie potencjalnych przyczyn zaburzenia płodności w oparciu o dostępną wiedzę naukową, ale również np. do:
- przeprowadzania powtórnych analiz za jakiś okres czasu, bez konieczności ponownego odczytywania tego samego kodu genetycznego, gdy niewątpliwie nastąpi dalszy postęp naukowy, z wykorzystaniem coraz doskonalszych narzędzi, umożliwiający np. nową interpretację niektórych wykrytych już wcześniej zmian genetycznych;
- przeprowadzenia innych analiz (w innym czasie) pod kątem, np. ryzyka wystąpienia choroby nowotworowej, czy innych zaburzeń, w stosunku do których istnieją lub mogą istnieć predyspozycje genetyczne;
- wprowadzania terapii precyzyjnych (spersonalizowanych), polegających np. na uwzględnianiu specyficznej odpowiedzi organizmu na zastosowaną terapię, np. na leki, która może być uwarunkowana genetycznie (farmakogenomika). Odczytanie eksomu i zachowanie uzyskanych danych z sekwencjonowania (odczytania sekwencji DNA metodą NGS – New Generation Sequencing), tzw. danych surowych, czy wstępnie opracowanych (patrz ryc. 3) oraz zachowanie ich na fizycznym nośniku (np. na pendrive) pozwala to nam na uzyskanie swojej własnej „książeczki” z zapisem informacji genetycznej organizmu.
Możemy ją później wykorzystać do ponownego, wielokrotnego odczytywania w zależności od potrzeb i w takim zakresie, na jaki pozwalają rozwój wiedzy naukowej i możliwości medycyny. Współczesna medycyna coraz szerzej sięga do informacji zawartej w DNA pacjenta, nie tylko w celu coraz bardziej precyzyjnego, spersonalizowanego, a tym samym skuteczniejszego leczenia, ale i celem zapobiegania grożącym mu chorobom.
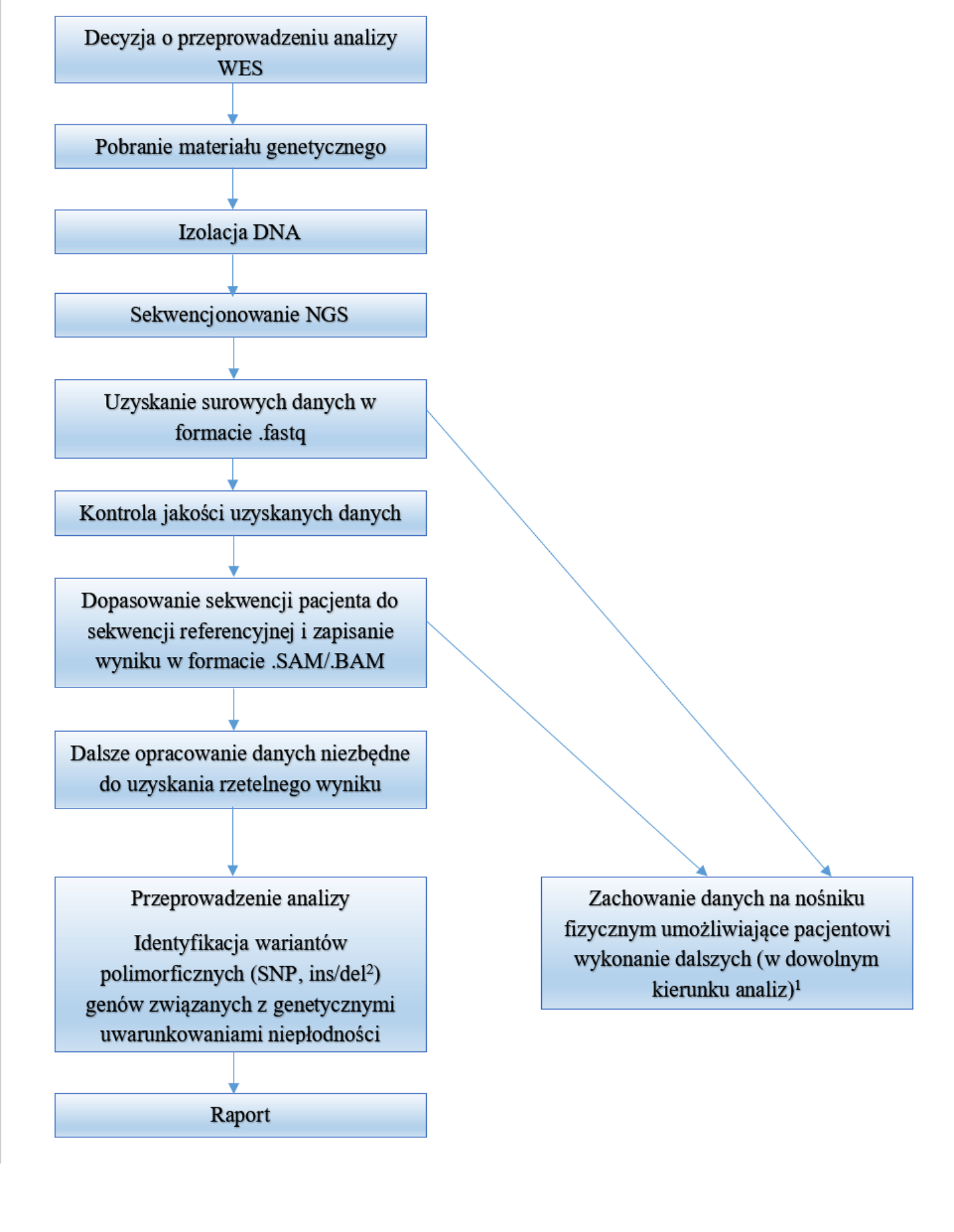
Rys.3 Schemat przebiegu analizy WES w IGiMM CMS CODE. Zachowane dane obejmują zarówno pliki .fastq jak i .SAM/.BAM tak aby umożliwić dopasowanie do innej sekwencji referencyjnej, czy dokonać ponownej analizy w późniejszym czasie.
1. Zachowane dane obejmują zarówno pliki .fastq jak i .SAM/.BAM tak aby umożliwić dopasowanie do innej sekwencji referencyjnej
2. SNP – zmiany pojedynczych nukleotydów, ins/del – kolejno wstawienie lub usunięcie jednego lub wielu nukleotydów
© Centrum Medyczne Code 2022

1. Geny i genom
Geny stanowią podstawową jednostkę dziedziczności. Geny są to odcinki DNA znajdującego się w jądrze komórkowym i mitochondriach, które kodują informacje dotyczące budowy białek lub krótkich kwasów rybonukleinowych (RNA). Zarówno białka jak i kwasy rybonukleinowe pełnią ważne funkcje strukturalne i funkcjonalne (w tym regulacyjne) w komórce. U człowieka znakomita większość genów koduje białka, które warunkują nie tylko pewne cechy fizyczne organizmu (takie jak kolor włosów czy oczu), są odpowiedzialne za prawidłowy przebieg różnych procesów zachodzących w naszym organizmie. Wadliwa budowa białek, a co za tym idzie, niemożność wykonywania przypisanej im funkcji może być powodem występowania wielu schorzeń. Obecnie uważa się, że człowiek posiada ok 20 -25 tys. genów kodujących białka. Całość informacji genetycznej zawartej w DNA nazywamy genomem. Jednak nie całe DNA zawiera informację, której sens rozumiemy. Występują w nim zarówno sekwencje kodujące białka/kwasy rybonukleinowe, nazwane sekwencjami eksonowymi jak i sekwencje niekodujące (introny). Funkcja intronów nie jest dobrze poznana. Co więcej, odcinek DNA składający się na jednostkę dziedziczności jaką jest gen, zawiera zarówno odcinki kodujące jak i niekodujące (introny) (ryc. 1).
Rys. 1 Schematyczne przedstawienie budowy ludzkiego genu zawierającego sekwencje kodujące i niekodujące
Większość genomu człowieka zbudowana jest z sekwencji niekodujących, sekwencje kodujące stanowią około 1,5 – 3% całej zawartości genomowego DNA. Genom możemy podzielić na części nazywane chromosomami, każdy gatunek ma z góry określoną ilość chromosomów. W przypadku człowieka liczba ta wynosi 22+1 (22 chromosomy somatyczne oraz chromosom płciowy) i taka ilość chromosomów znajduję się w komórce rozrodczej danej osoby. W komórkach somatycznych (budujących ludzki organizm), w ich jądrach komórkowych znajduje się dwukrotność tej liczby, gdyż każdy chromosom posiada również swoistą „kopię zapasową” zwaną chromatydą siostrzaną. To jaka para chromosomów płciowych znajduje się w komórce warunkuje płeć danej osoby: XX (kobieta) , XY (mężczyzna).
2. Analiza WES
Wszystkie sekwencje kodujące w genomie nazywamy eksomem. Procedura, której celem jest odczytanie (czyli sekwencjonowanie) sekwencji kodujących DNA znajdujących się w jądrze komórkowym, a następnie ich analizy nazywa się WES. WES (od ang. Whole Exome Sequencing) pozwala na odczytanie i interpretację informacji genetycznej zawartej jedynie w sekwencjach kodujących, czyli eksonach. Ograniczenie analizy genomowego DNA jedynie do sekwencji kodujących wynika głównie faktu, iż według aktualnego stanu wiedzy, jak na razie wartość kliniczna płynąca z badania obejmującego również introny jest niewielka. Sekwencje kodujące i produkty ich ekspresji, czyli głównie białka powstałe w wyniku odczytania tej informacji przez komórkę, są znacznie lepiej poznane. Analiza sekwencji kodujących umożliwia nam określenie, czy dany gen zawiera w swoim zapisie jakieś zmiany, co może się bezpośrednio przełożyć na zaburzenie struktury i funkcji kodowanego przez niego białka. Informacje uzyskane w toku analizy WES mogą nam posłużyć do określenia czy i w jakim stopniu wykryte zmiany mogą być związane z wystąpieniem danego schorzenia, a w przypadku wykonywanej przez nas analizy, jak mogą one wpływać na płodność badanego/ej pacjenta/ki.
3. Zastosowanie analizy WES w badaniu genetycznych
uwarunkowań niepłodności
Białka pełnią kluczową rolę w funkcjonowaniu organizmu w tym również odpowiadają w dużej mierze za prawidłowy przebieg procesu prokreacyjnego. Biorą one m.in. udział w procesie powstawania i dojrzewania komórek jajowych (oogeneza) oraz plemników (spermatogeneza). Odpowiadają za regulację wszelkiego rodzaju procesów związanych z płodnością, a także warunkują m.in. rozwój zarodka i przebieg ciąży. Problemy związane z niepłodnością zarówno męską jak i żeńską mają swe źródło w wielu, jeśli nie w większości przypadków, w nieprawidłowym funkcjonowaniu i/lub budowie białek związanych pośrednio lub bezpośrednio z procesami rozrodczymi. Przyczyny zaburzenia płodności to nie tylko problem nieprawidłowego funkcjonowania układu rozrodczego czy hormonalnego, ale trudna do pełnej identyfikacji i zdefiniowania ogromna liczba innych czynników (np. czynniki środowiskowe, dieta, czynniki odpowiedzialne za regulację ekspresji genów, dysfunkcja układu immunologicznego i wiele innych). Analiza WES daje unikatową możliwość wglądu/odczytania kodujących sekwencji DNA pacjenta i porównanie ich z sekwencją referencyjną opracowaną na podstawie uśrednionego wzorca ludzkiego genomu, korzystając z wyniku takiego porównania możemy przyjrzeć się zmianom w obrębie dowolnego genu. Wzorzec genomu był możliwy do opracowania dzięki realizacji jednego z największych współczesnych projektów badawczych – Human Genome Project. W jego realizacji uczestniczyło ponad 2 tys. naukowców kierowanych przez amerykańskiego naukowca, dr Francisa S. Collinsa. Główna część realizacji tego projektu została zakończona w 2003 roku. W analizie prowadzonej w celu identyfikacji genetycznych uwarunkowań niepłodności skupiamy się na analizie sekwencji tych genów, które według aktualnej wiedzy naukowej mają związek z zaburzeniami płodności męskiej i/lub żeńskiej w sposób pośredni lub bezpośredni. Jest to najbardziej szeroki z aktualnie dostępnych paneli badań, obejmujący znacznie szerszy zakres wykrywania genetycznych uwarunkowań zaburzeń płodności niż tradycyjne metody biologii molekularnej. WES jest szczególnie pomocnym narzędziem pozwalającym określić przyczynę zaburzeń zwłaszcza w przypadkach określanych mianem “idiopatycznych” (o nieznanej przyczynie). Wykorzystanie analizy WES do badań genetycznych uwarunkowań niepłodności jest innowacyjnym przedsięwzięciem Insytutu Genomiki i Medycyny Molekularnej (IGiMM) CMS Code (www.igmm.cmscode.pl). Badania w oparciu o analizę WES prowadzone są na całym świecie, głównie w placówkach naukowych, dużych jednostkach klinicznych i firmach prywatnych. Zastosowanie tej metody do identyfikacji genetycznych uwarunkowań zaburzeń płodności jest ciągle działalnością pionierską i nie stanowi jak dotąd rutynowej procedury diagnostycznej. Ogólny schemat wykonywania tej procedury w IGiMM CMS CODE przedstawia rys. 2.
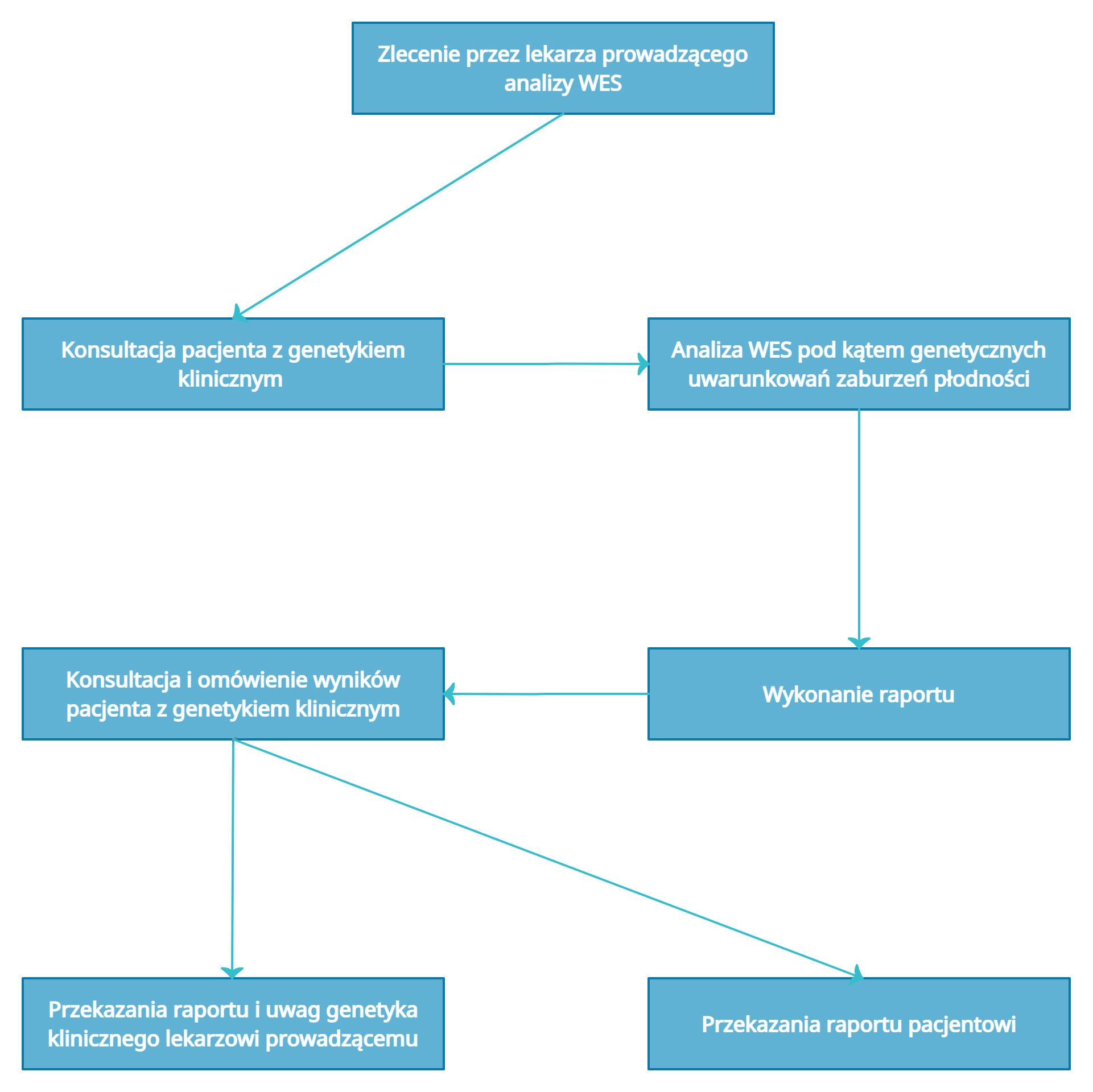
Rys.2 Ogólny schemat procedury wykonywania analizy WES
Szczegółowy sposób przeprowadzania samej analizy pokazany jest na ryc. 3. Głównym celem naszej działalności na poziomie badawczo-rozwojowym jest wdrożenie tej metody do praktyki medycznej w zakresie przyczynowego leczenie niepłodności.
4. Sekwencjonowanie (odczyt DNA), będące częścią analizy WES genetycznych uwarunkowań niepłodności, można wykorzystać znacznie szerzej.
Jak już wspomniano, białka są jednym z najbardziej podstawowych elementów strukturalnych i funkcjonalnych naszego organizmu. By dokonać analizy możliwie najszerszych przyczyn genetycznych uwarunkowań zaburzeń płodności, w których uczestniczą białka, dokonujemy odczytu całego eksomu (czyli większości lub prawie wszystkich genów kodujących białka), ale analizujemy tylko wybraną grupę genów i ich wariantów polimorficznych (czyli tych, które mają zmiany w swoim zapisie w stosunku do ich pierwotnych “wzorców”), a które na dzień dzisiejszy nauka łączy z możliwością ich wpływu na zaburzenia płodności występujące u badanego pacjenta/ki. Coraz częściej analiza WES wykorzystywana jest przede wszystkim w diagnostyce i personalizacji leczenia chorób nowotworowych, układu krążenia, chorób o podłożu genetycznym, a także w profilaktyce zdrowotnej. Zapis informacji genetycznej nie zmienia się zasadniczo przez cały okres naszego życia, od momentu zapłodnienia komórki jajowej i powstania zygoty, aż do śmierci. Ta część analizy WES, która polega na odczytaniu informacji genetycznej, dostarcza pacjentowi rodzaj “książeczki” z zapisem “planu budowy” białek tworzących jego organizm. Przeprowadzenie odczytu zapisu informacji genetycznej organizmu badanego pacjenta może więc posłużyć nie tylko do głównego celu, jakim jest poszukiwanie potencjalnych przyczyn zaburzenia płodności w oparciu o dostępną wiedzę naukową, ale również np. do:
- przeprowadzania powtórnych analiz za jakiś okres czasu, bez konieczności ponownego odczytywania tego samego kodu genetycznego, gdy niewątpliwie nastąpi dalszy postęp naukowy, z wykorzystaniem coraz doskonalszych narzędzi, umożliwiający np. nową interpretację niektórych wykrytych już wcześniej zmian genetycznych;
- przeprowadzenia innych analiz (w innym czasie) pod kątem, np. ryzyka wystąpienia choroby nowotworowej, czy innych zaburzeń, w stosunku do których istnieją lub mogą istnieć predyspozycje genetyczne;
- wprowadzania terapii precyzyjnych (spersonalizowanych), polegających np. na uwzględnianiu specyficznej odpowiedzi organizmu na zastosowaną terapię, np. na leki, która może być uwarunkowana genetycznie (farmakogenomika). Odczytanie eksomu i zachowanie uzyskanych danych z sekwencjonowania (odczytania sekwencji DNA metodą NGS – New Generation Sequencnig), tzw. danych surowych, czy wstępnie opracowanych (patrz ryc. 3) oraz zachowanie ich na fizycznym nośniku (np. na pendrive) pozwala to nam na uzyskanie swojej własnej “książeczki” z zapisem informacji genetycznej organizmu.
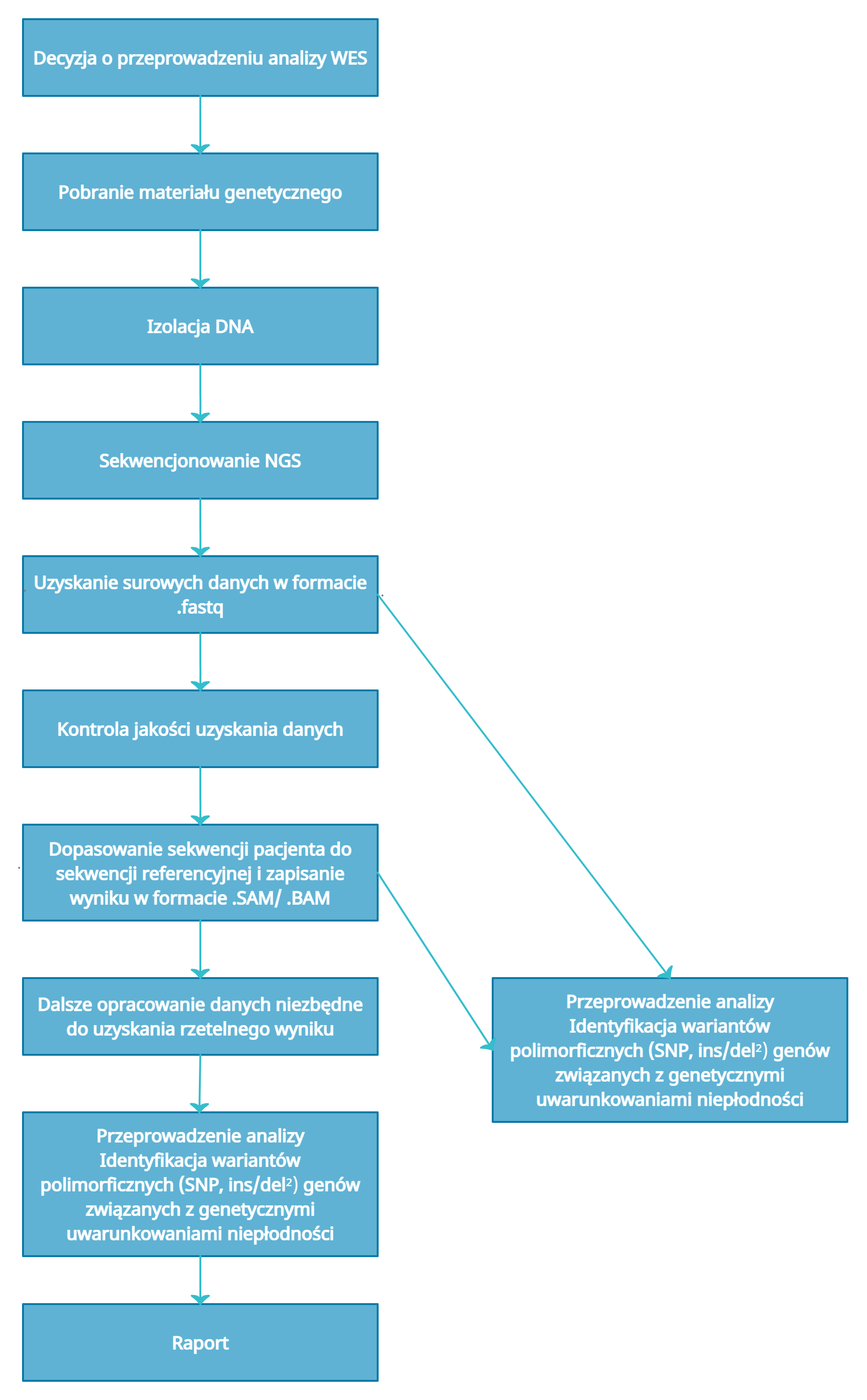
Rys.3 Schemat przebiegu analizy WES w IGiMM CMS CODE. Zachowane dane obejmują zarówno pliki .fastq jak i .SAM/.BAM tak aby umożliwić dopasowanie do innej sekwencji referencyjnej, czy dokonać ponownej analizy w późniejszym czasie. 2. SNP – zmiany pojedynczych nukleotydów, ins/del – kolejno wstawienie lub usunięcie jednego lub wielu nukleotydów
Możemy ją później wykorzystać do ponownego, wielokrotnego odczytywania w zależności od potrzeb i w takim zakresie, na jaki pozwalają rozwój wiedzy naukowej i możliwości medycyny. Współczesna medycyna coraz szerzej sięga do informacji zawartej w DNA pacjenta, nie tylko w celu coraz bardziej precyzyjnego, spersonalizowanego, a tym samym skuteczniejszego leczenia, ale i zapobiegania grożącym mu chorobom.
© Centrum Medyczne Code 2022